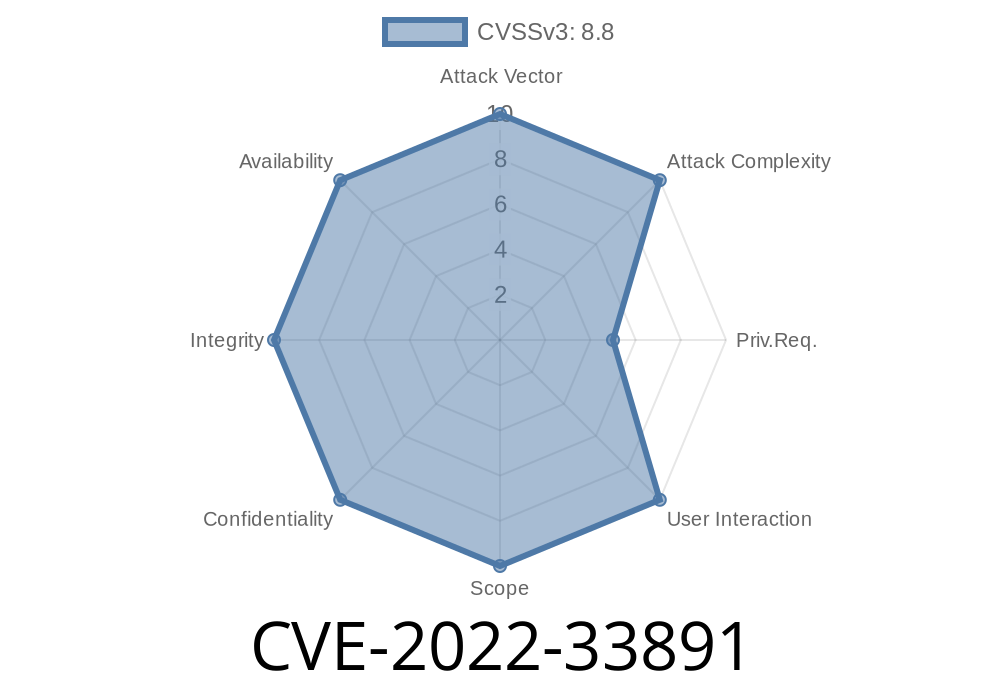
There is no known way to exploit this vulnerability if Apache Spark is installed with a different user name than the one configured on the system. We recommend installing Apache Spark with a different user name than the one defined on the system, such as 'apache' instead of 'spark'. This will help limit the damage if someone were to discover this security issue. We are working on a fix for this issue in version 3.2.0.
Affected versions: 3.0.3, 3.1.1 to 3.1.2, 3.2.0 to 3.2.1 Fixed versions: 3.2.2 Docker users should upgrade to a fixed version, as they are likely using a pre-3.2.2 version. We are aware of active attempts to exploit this vulnerability on the internet. Due to the risk of further exposure, we are not warning against exploitation, but strongly recommend upgrading to a fixed version.
Apache Spark is an open-source distributed computing platform for big data analysis. It is a fast, easy to use, general-purpose data processing engine that can run on cluster of commodity hardware. Apache Spark provides a distributed data processing engine. Data processing operations such as sorting, filtering, mapping, and joining data sets together can be run across the cluster in a fast, fault-tolerant, and distributed fashion. Apache Spark can work with both structured and unstructured data sets. It provides a high-level
Technical Overview of the Vulnerability
The vulnerability is caused by Apache Spark running as a setuid root process, which can be exploited to gain access to sensitive information or system control. The core of the vulnerability is in the way that Spark's security checks are performed when it starts up. When started by a user with administrative privileges on the operating system, Apache Spark will run with full privileges as a setuid root process, with no further checks done. The issue has been resolved in Apache Spark 3.2.2, but if you are still running an older version of Spark, we recommend upgrading to avoid being exposed to future attacks.
Pre-requisites for Spark vulnerability
This vulnerability requires the following:
- Apache Spark installed on a system that has a user named 'spark' configured on it.
- The system where Spark is installed must have administrative privileges to access the 'spark' user name.
- This vulnerability can only be exploited if logged in to the system as the user 'spark'.
- This vulnerability can only be exploited by a remote attacker who has admin rights to an Apache Spark installation and knows of this issue and how it can be exploited.
Timeline
Published on: 07/18/2022 07:15:00 UTC
Last modified on: 09/08/2022 17:15:00 UTC